
News center
资讯中心
资讯中心当前位置:首页>>资讯详情
一文教会你用python开发爬虫
发布:武汉灵犀教育发布时间:2019-06-26
Python语言简洁、易懂、易学,是入门编程语言的首选。如今,python在网络爬虫、人工智能、大数据等领域都有很好的应用。很多人更是从python开始编写自己的第一个爬虫程序。今天向大家介绍一下Python爬虫的一些知识和常用类库的用法,希望能对大家有所帮助。
构建一个网络爬虫基本可以分成以下几个步骤:
· 发起网络请求
· 获取网页资源
· 解析网页获取目标数据
发起网络请求常用的类库有标准库urllib以及第三方的requests库。解析网页常用的类库有的BeautifulSoup。另外还有一些专业的爬虫框架,其中比较出名的就是scrapy。下面我们一起来详细的看一下这些常用的库和框架。
1. 标准库urllib
urllib是Python自带的库,优点是不需要安装,缺点是urllib属于偏底层的库,使用起来比较麻烦。下面是urllib发起请求的一个简单例子。
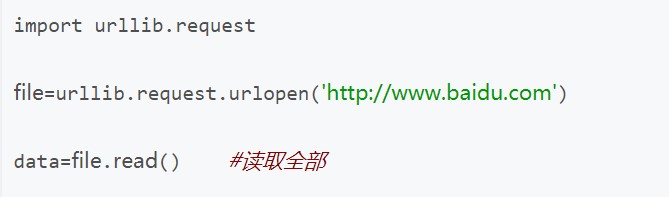
如果想要添加请求头(headers)或者代理(proxy)等,则需要构建低层的handler,比较麻烦。
2. requests
requests是Kenneth Reitz大神的著名作品之一,优点就是极度简单和好用。首先来安装requests。
pip install requests
下面是一个简单的例子,在requests中使用请求头和代理时,代码量少多了,也更易读。

requests还可以方便的发送表单数据,模拟用户登录。返回的Response对象还包含了状态码、header、raw、cookies等很多有用的信息。
更多关于requests的使用大家可以参阅其中文文档,虽然比官方落后几个小版本号,不过无伤大雅,可以放心参阅。
http://cn.python-requests.org/zh_CN/latest/
3. Beautifulsoup
利用前面介绍的requests类库,我们可以轻易地获取HTML代码,但是为了从HTML中找到所需的数据,我们还需要HTML/XML解析库,BeautifulSoup就是这么一个常用的库。首先先来安装它:
pip install beautifulsoup4
在使用BeautifulSoup进行页面解析的时候,首先需要创建一个HTML树,然后从树中查找节点。BeautifulSoup主要有两种查找节点的办法,第一种是使用find和find_all方法,第二种方法是使用select方法用css选择器。

BeautifulSoup也有中文文档,同样也是稍微落后两个小版本,影响不大。
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
4. Scrapy
以上介绍的几个类库都是各自有各自的作用,把它们结合起来可以达到编写基础爬虫的目的,但是要说专业的爬虫框架,还是得谈谈scrapy。作为一个著名的爬虫框架,scrapy将爬虫模型框架化和模块化,利用scrapy,我们可以迅速生成功能强大的爬虫。
Scrapy的执行框架如下所示:
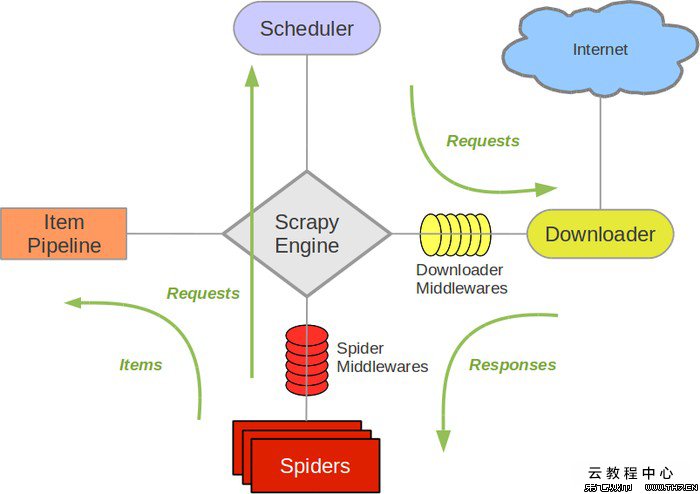
简单介绍下scrapy的使用。
1) 安装scrapy。
pip install scrapy
2) 然后创建scrapy项目并添加一个新爬虫。命令如下:
scrapy startproject myproject
cd myproject
scrapy genspider baiduSpider baidu.com
3) 编写items.py文件,定义将要爬取的目标数据
4) 然后修改spider.py文件,编写自己的爬虫处理相关代码。
5) 编写pipelines来处理抓取到的数据
6) 修改settings文件,应用pipelines
学会这些基础的类库,我们就可以编写基本的网络爬虫了。掌握了Scrapy框架则可以编写更强大的爬虫。
希望这个分享对大家有帮助,也欢迎大家与我探讨更多的技术细节,我的联系QQ:1759667545

